
기본 환경
- kubectl 설치
- eks 설치
- helm 설치
- terraform 설치
- vs코드 상에서 진행 예정
저는 우선 무료인 GCP버전에서 spring cloud로 개발하고 그것을 AWS의 kubernetes로 옮기는 과정을 거쳤습니다.
개발 환경은 front는 Next.js, back은 MSA로 Spring Boot를 적용했습니다.
아래 방법은 쿠버네티스를 MSA로 구축하기 위한 제가 적용한 기본 방법입니다.
AWS환경에서 만들었던 terraform 코드들(아래)
eks-cluster.tf
eks-nodegroup.tf
iam-roles.tf
internet_gateway.tf
outputs.tf(cluster name , endpoint)
providers.tf
route_table_association.tf
route_tatble.tf
security-group.tf
subnet.tf
variable.tf
vpc.tf
이런 기본 aws 클러스터 설정을 적용합니다.
해당 파일은 terraform으로 구성해서 terraform apply를 적용했습니다.
파일을 S3와 연동해서 사용해 코드의 변화를 인식하도록 만들기 위해 EBS-CSI-Driver를 연동했습니다.
로드벨런서를 사용 하기 위해 aws-load-balancer-controller를 설치해줬습니다.
git action을 통해 CI를 하기 위해 gitaction 설정을 했습니다.(Jenkins보다 쉬운 유입, 빠른 속도 때문에 적용하게 되었습니다.)
Jenkins와 GitAction + ArgoCD를 비교해보자면
Jenkins는 배포할 때, 서버의 용량이 작은 편이라면 순간적인 메모리 사용이 급증해서 서버가 연결이 끊기거나 문제가 발생하는 경우가 생기더라구요. 하지만 GitAction과 ArgoCD는 상대적으로 메모리 사용량이 적고, 개발자가 git에서 자신의 작성 코드가 올바르게 이미지가 생성되는지 확인할수 있다는 점을 바로 확인할 수 있다는 점이 좋았습니다. 다만 devops입장에서 git과 도커허브, ArgoCD 전체를 관리하는게 조금 번거로워서 한번에 확인할 수 있는 UI가 있으면 좋겠다는 생각을 했습니다.
front를 배포할때 통신하기 위해 ingress-nginx-controller를 설치해줬습니다.
여기서 문제는 spring cloud의 gateway 서버처럼 하나의 도메인을 가지고 분산해서 로드벨런싱을 하려면 L7계층에서 해야하기 때문에 ALB만을 사용해야 되는것인가
vs
각 서버마다 다르게 적용해도 백엔드 서버니깐 그렇게 문제되지 않는다로 NLB와 고민을 했었던것 같아요.
CD는 argoCD를 적용했습니다.
이렇게 적용해주면
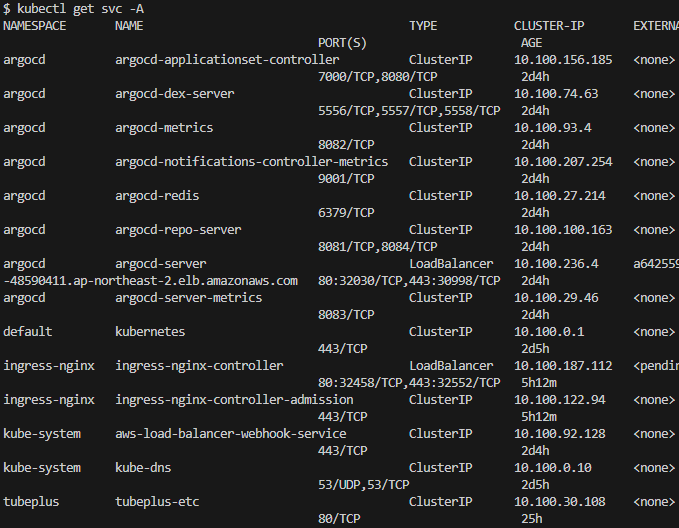
service 로직만 보았을 대 위와 같이 설정되는 것을 알수 있습니다.
모든 backend 로직은 clusterIP로 설정하고 내부 네트워크 통신을 했습니다. Profix로 http통신을 url로 인식하도록 만들었고, 이방법을 통해
http://<host>:80/api/v1/<msa file name>으로 구분을 했습니다.
사실, header를 통해 구분할 수 있었지만 spring eureka를 통해 개발하는 방법을 적용할 때 이미 url로 구분하고 있었기에 그대로 구현했습니다.
또한 비용을 절약하기 위한 방법이 하나 더있었어요 ㅎㅎ
처음에는 비용의 절감을 위해 terraform destory를 개발 직후 해줬지만, 매일 argoCD설정, addon설정을 매일 1시간씩 적용하게 되었고 node를 0으로 만드는 방법으로 변경하게 되었습니다.
변경 방법은 아래와 같습니다.
resource "aws_eks_node_group" "tubeplus-eks-nodegroup" {
cluster_name = aws_eks_cluster.tubeplus-eks-cluster.name
node_group_name = "tubeplus-eks-nodegroup"
node_role_arn = aws_iam_role.tubeplus-eks_iam_nodes.arn
subnet_ids = aws_subnet.tubeplus-public-subnet[*].id
ami_type = "AL2_x86_64"
capacity_type = "ON_DEMAND"
instance_types = ["t3a.medium"]
disk_size = 20
scaling_config {
desired_size = 0
max_size = 1
min_size = 0
# desired_size = 2
# max_size = 3
# min_size = 1 이부분을 변경해서 terraform apply적용
}
depends_on = [
aws_iam_role_policy_attachment.tubeplus-eks_iam_cluster_AmazonEKSWorkerNodePolicy,
aws_iam_role_policy_attachment.tubeplus-eks_iam_cluster_AmazonEKS_CNI_Policy,
aws_iam_role_policy_attachment.tubeplus-eks_iam_cluster_AmazonEC2ContainerRegistryReadOnly
]
tags = {
"Name" = "tubeplus-EKS-WORKER-NODES"
}
}이렇게만 적용해도 비용의 대다수를 아낄수 있습니다.
참고 . 쿠버네티스 핵심 키워드
pod : 어떤 애플리케이션
replicaSet : 얼마나
node, namespace : 어디에
deployment : 어떤 방식으로 배포
service, endpoints : 트래픽 로드밸런싱 방법
Ingress : 네트워크 연결 방법(aws-load-balancer-controller 에드온 설치 필요)
그리고 기본적인 설계를 하기위해서 'helm create helm-chart' 를 하면
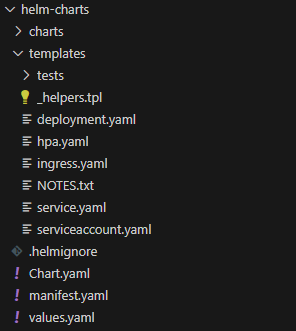
이렇게 구성이 되는데 manifest.yaml의 경우 helm chart의 구성요소를 기본 service 로직과 똑같이 구현되는지 확인하는 용도로 만들었습니다.
그리고 values.yaml에 대해 이해를 하기 위해 _helpers.tpl을 뜯어보면 잘될것입니다. ㅎㅎ
values.yaml로 사용을 했을 때, 자신의 서비스 로직에 맞게 개발을 하시면 됩니다.
argo CD의 경우 기본 홈페이지에 들어가서 설치하시거나 helm을 이용해서 설치할 수 있습니다.
하지만 가장 간단한 건 기본 홈페이지에서 설치하는게 편합니다 ㅎㅎ
CI/CD방법
1단계. 배포 branch에 github merge를 통해 올린다.
2단계. git action을 통해 docker hub에 이미지를 올린다.
3단계. git action을 통해 value.yaml을 새로 갱신한다.
4단계. argoCD는 value.yaml이 변경되면 docker hub의 이미지를 불러온다.
5단계. 불러온 이미지를 이용해 deploy를 적용한다.
사실 위와 방법을 구현하는데 수많은 수행착오가 있었습니다. jenkins를 통해 pipeline이나 shell을 이용하던 익숙한 방법을 버리고 새로 적용해보았습니다.

jenkins를 통해 CI/CD를 모두 적용할 때 저의 dev 배포판은 size가 작았기에 1분 21초 정도 걸리는 것을 알수 있습니다.
또한 상태를 확인하기 위해 항상 jenkins에서 들어가서 확인했습니다.
하지만
git action을 통해 CI/CD를 할 때, 1분 28초 정도에 상태를 git에서 바로 확인할 수 있습니다.

비록 최종 상태 적용은 argo에서 되지만 배포자체에 문제가 있는지에 대한 문제는 git에서 바로 확인할 수 있어서 팀원들이 보다 쉽게 확인한 것같습니다.
'CI&CD > Kubernetes' 카테고리의 다른 글
| Cloud Native Spring In Action 7장 정리 (2) | 2024.10.11 |
|---|
기본 환경
- kubectl 설치
- eks 설치
- helm 설치
- terraform 설치
- vs코드 상에서 진행 예정
저는 우선 무료인 GCP버전에서 spring cloud로 개발하고 그것을 AWS의 kubernetes로 옮기는 과정을 거쳤습니다.
개발 환경은 front는 Next.js, back은 MSA로 Spring Boot를 적용했습니다.
아래 방법은 쿠버네티스를 MSA로 구축하기 위한 제가 적용한 기본 방법입니다.
AWS환경에서 만들었던 terraform 코드들(아래)
eks-cluster.tf
eks-nodegroup.tf
iam-roles.tf
internet_gateway.tf
outputs.tf(cluster name , endpoint)
providers.tf
route_table_association.tf
route_tatble.tf
security-group.tf
subnet.tf
variable.tf
vpc.tf
이런 기본 aws 클러스터 설정을 적용합니다.
해당 파일은 terraform으로 구성해서 terraform apply를 적용했습니다.
파일을 S3와 연동해서 사용해 코드의 변화를 인식하도록 만들기 위해 EBS-CSI-Driver를 연동했습니다.
로드벨런서를 사용 하기 위해 aws-load-balancer-controller를 설치해줬습니다.
git action을 통해 CI를 하기 위해 gitaction 설정을 했습니다.(Jenkins보다 쉬운 유입, 빠른 속도 때문에 적용하게 되었습니다.)
Jenkins와 GitAction + ArgoCD를 비교해보자면
Jenkins는 배포할 때, 서버의 용량이 작은 편이라면 순간적인 메모리 사용이 급증해서 서버가 연결이 끊기거나 문제가 발생하는 경우가 생기더라구요. 하지만 GitAction과 ArgoCD는 상대적으로 메모리 사용량이 적고, 개발자가 git에서 자신의 작성 코드가 올바르게 이미지가 생성되는지 확인할수 있다는 점을 바로 확인할 수 있다는 점이 좋았습니다. 다만 devops입장에서 git과 도커허브, ArgoCD 전체를 관리하는게 조금 번거로워서 한번에 확인할 수 있는 UI가 있으면 좋겠다는 생각을 했습니다.
front를 배포할때 통신하기 위해 ingress-nginx-controller를 설치해줬습니다.
여기서 문제는 spring cloud의 gateway 서버처럼 하나의 도메인을 가지고 분산해서 로드벨런싱을 하려면 L7계층에서 해야하기 때문에 ALB만을 사용해야 되는것인가
vs
각 서버마다 다르게 적용해도 백엔드 서버니깐 그렇게 문제되지 않는다로 NLB와 고민을 했었던것 같아요.
CD는 argoCD를 적용했습니다.
이렇게 적용해주면
service 로직만 보았을 대 위와 같이 설정되는 것을 알수 있습니다.
모든 backend 로직은 clusterIP로 설정하고 내부 네트워크 통신을 했습니다. Profix로 http통신을 url로 인식하도록 만들었고, 이방법을 통해
http://<host>:80/api/v1/<msa file name>으로 구분을 했습니다.
사실, header를 통해 구분할 수 있었지만 spring eureka를 통해 개발하는 방법을 적용할 때 이미 url로 구분하고 있었기에 그대로 구현했습니다.
또한 비용을 절약하기 위한 방법이 하나 더있었어요 ㅎㅎ
처음에는 비용의 절감을 위해 terraform destory를 개발 직후 해줬지만, 매일 argoCD설정, addon설정을 매일 1시간씩 적용하게 되었고 node를 0으로 만드는 방법으로 변경하게 되었습니다.
변경 방법은 아래와 같습니다.
resource "aws_eks_node_group" "tubeplus-eks-nodegroup" {
cluster_name = aws_eks_cluster.tubeplus-eks-cluster.name
node_group_name = "tubeplus-eks-nodegroup"
node_role_arn = aws_iam_role.tubeplus-eks_iam_nodes.arn
subnet_ids = aws_subnet.tubeplus-public-subnet[*].id
ami_type = "AL2_x86_64"
capacity_type = "ON_DEMAND"
instance_types = ["t3a.medium"]
disk_size = 20
scaling_config {
desired_size = 0
max_size = 1
min_size = 0
# desired_size = 2
# max_size = 3
# min_size = 1 이부분을 변경해서 terraform apply적용
}
depends_on = [
aws_iam_role_policy_attachment.tubeplus-eks_iam_cluster_AmazonEKSWorkerNodePolicy,
aws_iam_role_policy_attachment.tubeplus-eks_iam_cluster_AmazonEKS_CNI_Policy,
aws_iam_role_policy_attachment.tubeplus-eks_iam_cluster_AmazonEC2ContainerRegistryReadOnly
]
tags = {
"Name" = "tubeplus-EKS-WORKER-NODES"
}
}이렇게만 적용해도 비용의 대다수를 아낄수 있습니다.
참고 . 쿠버네티스 핵심 키워드
pod : 어떤 애플리케이션
replicaSet : 얼마나
node, namespace : 어디에
deployment : 어떤 방식으로 배포
service, endpoints : 트래픽 로드밸런싱 방법
Ingress : 네트워크 연결 방법(aws-load-balancer-controller 에드온 설치 필요)
그리고 기본적인 설계를 하기위해서 'helm create helm-chart' 를 하면
이렇게 구성이 되는데 manifest.yaml의 경우 helm chart의 구성요소를 기본 service 로직과 똑같이 구현되는지 확인하는 용도로 만들었습니다.
그리고 values.yaml에 대해 이해를 하기 위해 _helpers.tpl을 뜯어보면 잘될것입니다. ㅎㅎ
values.yaml로 사용을 했을 때, 자신의 서비스 로직에 맞게 개발을 하시면 됩니다.
argo CD의 경우 기본 홈페이지에 들어가서 설치하시거나 helm을 이용해서 설치할 수 있습니다.
하지만 가장 간단한 건 기본 홈페이지에서 설치하는게 편합니다 ㅎㅎ
CI/CD방법
1단계. 배포 branch에 github merge를 통해 올린다.
2단계. git action을 통해 docker hub에 이미지를 올린다.
3단계. git action을 통해 value.yaml을 새로 갱신한다.
4단계. argoCD는 value.yaml이 변경되면 docker hub의 이미지를 불러온다.
5단계. 불러온 이미지를 이용해 deploy를 적용한다.
사실 위와 방법을 구현하는데 수많은 수행착오가 있었습니다. jenkins를 통해 pipeline이나 shell을 이용하던 익숙한 방법을 버리고 새로 적용해보았습니다.
jenkins를 통해 CI/CD를 모두 적용할 때 저의 dev 배포판은 size가 작았기에 1분 21초 정도 걸리는 것을 알수 있습니다.
또한 상태를 확인하기 위해 항상 jenkins에서 들어가서 확인했습니다.
하지만
git action을 통해 CI/CD를 할 때, 1분 28초 정도에 상태를 git에서 바로 확인할 수 있습니다.
비록 최종 상태 적용은 argo에서 되지만 배포자체에 문제가 있는지에 대한 문제는 git에서 바로 확인할 수 있어서 팀원들이 보다 쉽게 확인한 것같습니다.
'CI&CD > Kubernetes' 카테고리의 다른 글
| Cloud Native Spring In Action 7장 정리 (2) | 2024.10.11 |
|---|