

두번째 프로젝트는 소기의 상을 받았던 프로젝트였습니다.
이건 우수상을 받을수 있었습니다.

저희 조가 추구하고자 하던 바는 "뉴스를 읽는 사람이 이해할수 있게 뉴스들을 추천할 수 있게 만들자" 였습니다.
뉴스를 보면 모르는 단어나 왜? 라는 물음이 생기는 경우가 생깁니다.
이 때, 모르는 단어가 요즘 뜨는 키워드인 경우, 날짜 순으로 가장 이슈가 된 날이 언제인지 그래프로 보여주고
해당 날짜의 뉴스를 통해 이해시켜주는 것입니다.

어떻게 구현했는지 궁금하시죠? ㅎㅎ
이를 구현하기 위해서 3가지가 필수적으로 구현되어야 했습니다.
1. 뉴스들의 군집을 모아주는 알고리즘
2. 뉴스들을 빠르게 처리해주는 클러스터링
3. 빠르게 기사나 필터링을 해주는 인덱싱

이렇게 중요한 3가지를 제외하고, 추가적으로 구현한 기능은
4. 원하는 일자의 대표 키워드들을 워드 클라우딩 형태로 보여주는 것

5. 키워드들 중 대표 10가지에 관련된 기사들 중 대표적인 기사를 아래처럼 소개하는 것
이었습니다.
6. 뉴스들의 문장 중 가장 중요하다고 생각되는 문장 3문장을 골라 3줄 요약을 해주었습니다.
저희가 구현한 아키텍처는 다음과 같습니다.
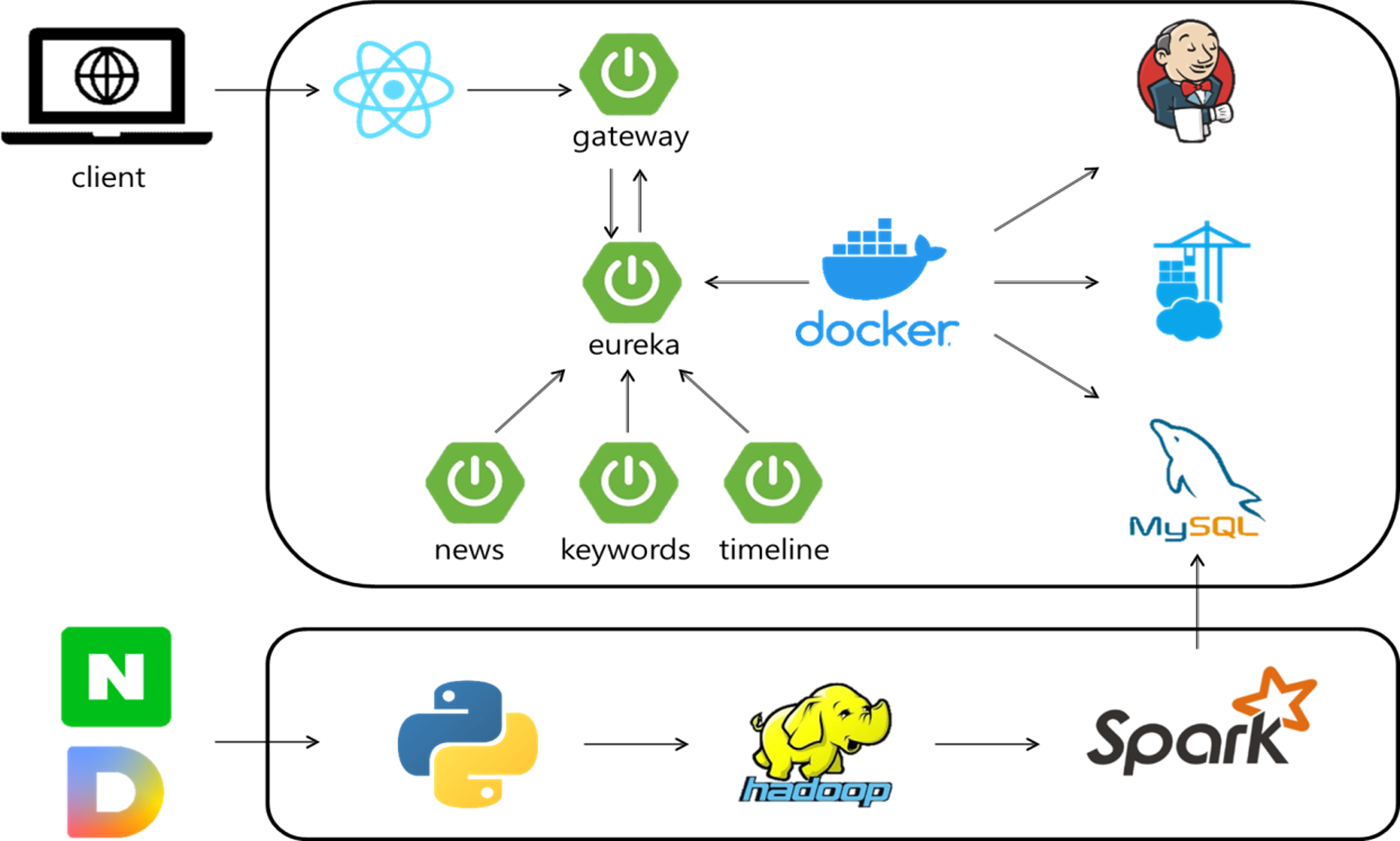
우선, 뉴스들의 군집을 모아주는 알고리즘을 구현하기 위해서 뉴스들의 키워드를 분석할 필요성이 있었습니다.
키워드 중에서 명사들을 모아 분석했습니다. 동사의 경우 중요한 말도 있지만 투자 시간 대비 효율이 많이 나지 않았기 때문입니다.
그 중에서 키워드 분석을 할 라이브러리가 필요했습니다.
KoNLPy와 바른 ai를 비교했을 때, 신조어도 나오는 당일 뉴스를 비교해야 했기 때문에 직접 비교를 통해 선택하게 되었습니다.

바른 AI의 경우 Transformer 모델(넓게보면 chat gpt 기반)을 기반으로 하는 라이브러리로 한국어의 특성에 최적화된 자연어 처리기입니다.
바른과 함께 찾은 또다른 라이브러리는 koNLPy(코엔엘파이)였습니다. 대중적으로 사용되고 있는 라이브러리 입니다.
둘 중 어떤 방식이 좋을 것인가를 판단하기 위해 같은 기사를 형태소분석시킨 결과 KoNLPy은 새롭게 생긴 신조어들을 제대로 인식하지 못하고 분리시켜 보여주었습니다. 하지만 바른은 최신 신조어까지 잘 학습이 되어 큐코노미나 호모마스쿠스라는 신조어들을 온전하게 분리하는 것을 확인할 수 있었습니다.
이러한 결과를 통해 저희는 바른 라이브러리를 선택하게 되었습니다.

다음은 단어 벡터화에 쓰인 TF-IDF입니다.
TF는 기사 내에서 얼마나 많이 나왔는가입니다. IDF는 많은 기사에서 언급된 단어들의 비중을 줄여주게 되는 것입니다. 이렇게 TF와 IDF가 곱해지면 각 뉴스의 특색을 나타내는 단어들이 높은 값을 가지게 됩니다.
군집 분석은 DBSCAN과 k-means에서 고민을 했는데요.

k-means는 k개의 중심점을 기반으로 군집을 형성하는 방법으로 군집의 개수를 미리 정해야 하는 분석 기법입니다.
반면에 DBSCAN은 밀도를 기반으로 군집을 형성하는 방법으로 개수를 정하지 않아도 된다는 특징이 있습니다.
저희는 단어 벡터가 밀도를 기반으로 구성되었다고 판단하였고 그 날의 군집의 개수를 특정할 수 없기 때문에 DBSCAN이 더욱더 적절한 기법이라 생각하여 DBSCAN 기법을 사용하였습니다.
코드 결과를 보면
형태소 분석 결과

TF-IDF 결과

DBSCAN 결과

처럼 기준을 가지고 값이 묶이게 됩니다. TF-IDF의 경우 가로 세로 줄이 매우 많아서 0.0으로 나온것처럼 보이지만,, 무려 가로가 19850이랍니다. 저 데이터가 겨우 7일 데이터로 묶인 결과입니다.
저희는 초반에는 1일 -> 7일 데이터로 늘렸다가 데이터의 정확성을 위해서 40일의 데이터를 묶어서 산출했습니다.
이 과정에서 당연히 시간이 엄청 걸릴것 같죠..!
모든 작업은 스파크를 통해서 분산처리를 했습니다. 그리고 하루의 데이터를 처리하는 데 걸린 시간은 31분 56초!

과정은 다음과 같습니다.
우선, 기사를 다음과 네이버에서 클러스터링을 진행합니다. 그 결과를 hdfs에 저장하고 pipeline을 통해 자동으로 8개의 파티션으로 나눠서 스파크에서 연산을 진행합니다. 이때 스파크에서는 DataFrame으로 진행했습니다. 그렇게 군집이 되면 json파일로 저장하게 되고, 저장된 파일이 증가하면 그 날짜를 기준으로 40개의 이전 데이터를 가져와서 군집분석을 하게 됩니다.
그리고 이 프로젝트에서 가장 중요한 기능 중 하나는 검색이겠죠?
얼마나 빨리 검색을 하냐에 따라 유저가 느끼는 체감 편리성이 다르니깐!!

저희는 인덱스 테이블을 사용했습니다.
약간의 방법의 차이였지만, 이러한 변화는 메모리 저장과 테이블의 변화로 결과 시간의 99% 이상 단축되었습니다.
'프로젝트 > 프로젝트' 카테고리의 다른 글
| 현업 프로젝트(기술스텍 변경) FireBase에서 SpringBoot로 (1) | 2024.09.08 |
|---|---|
| 세번째 프로젝트 Semse 복기 (0) | 2024.02.20 |
| 첫번째 프로젝트 Sodam 복기(2) (0) | 2023.02.20 |
| 첫번째 프로젝트 Sodam 복기(1) (3) | 2023.02.19 |